Testing Maia's Puzzle Performance
How strong are the Maia engines when solving tactics?Since I'm interested in ways to use engines to make chess more accessible to humans, I find the Maia project really fascinating.
The idea behind the Maia project was to train neural networks on online blitz games in order to emulate human play. They trained different network files for the LC0 engine for each 100 rating point band from 1100 to 1900 (you can find the files on their Github page). Their engines performed better at the task of predicting human moves in a given rating band than any other engine.
The team behind the project has also written another paper where they made individualised engines in order to predict moves by specific players. They had very interesting results and I've written about them here.
Background to the Puzzle Tests
My original idea was to use the different Maia models to classify the level of errors. I wanted to analyse a position where a player made an error with each Maia model and look at the top move of each model. The “rating” of the error would then be the rating of the highest rated Maia model which would have played the incorrect move.
For example, if the models rated from 1100-1400 wouldn't find the correct move in a given position and the models rated 1500+ would, then the error would be classified as a 1400 level error.
However, when doing some tests I noticed that for most positions, the different models agreed on the move, meaning that they either all played the correct move or all made a mistake. There were also some strange instances where a lower rated model found the correct move and the higher rated models didn't.
In order to investigate this, I decided to test the performance of different Maia models on tactics puzzles.
Puzzle Performance
I downloaded the puzzle database from Lichess and filtered out any puzzles with less than 20,000 plays. The reason was that I wanted the puzzles to have enough plays in order for their rating to be reliable and there were simply way too many puzzles to go through all or even a large part of them. In the end, I was left with 20,552 puzzles, which should be more than enough.
In order to get a good idea of the strength of the models, I split the puzzles into 300 point rating bands and looked at these bands separately.
Note that I only used 1 node to analyse the puzzles, since the authors have mentioned in their paper that using tree search (i.e. more than 1 node) has decreased the move-matching accuracy of the models. Increasing the node count would improve the performance, but since the models move further away from human play it would defeat the point of using Maia models in the first place.
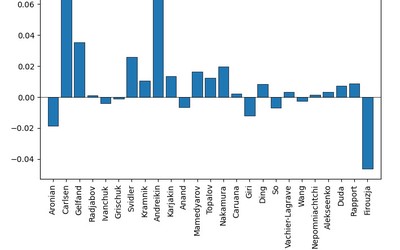
I also recorded full solutions, where the model got every move of the solution in the puzzle database correct and partial solutions, where at least the first move was correct. In the graph below, the darker shades represent the score when only counting full solutions and the lighter shades also include partial solutions.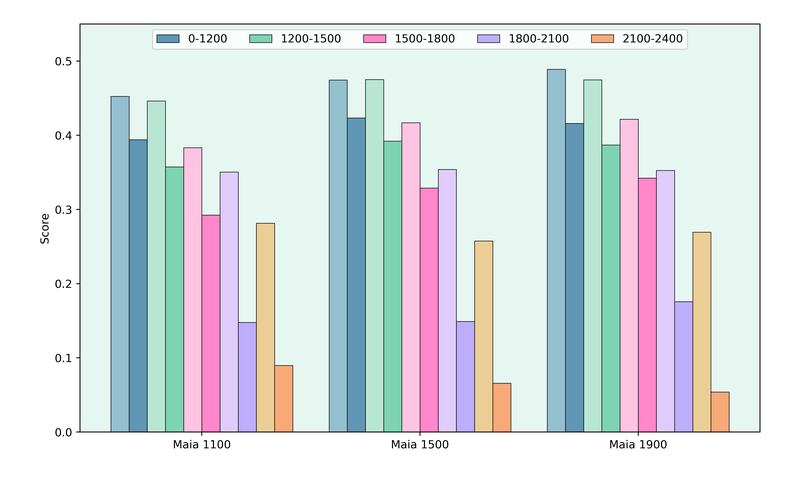
I was very surprised that there was hardly any difference between the scores of the Maia models. I also calculated the performance rating of the models to have a direct rating comparison.
| Maia 1100 | Maia 1500 | Maia 1900 | |
|---|---|---|---|
| Performance Rating (partial solution) | 1411 | 1434 | 1435 |
| Performance Rating (full solution) | 1336 | 1362 | 1363 |
I found it hard to believe that the performance differences are so small, so I decided to look at the Maia bots on Lichess. To my surprise, the ratings of the 1100 and 1900 bots were also within 200 rating points, so I don't think that something went wrong in my tests.
Since the differences between the models are so small, I don't think that I can use them to classify the level of a mistake.
Another option would be to use conventional engines and vary their depth to see when they discover a move. The idea behind this is that the engine needs to search deeper in order to find more difficult moves. But my problem with that approach is that it's difficult to relate the depth to human performance since it might depend a lot on the type of position. Engines also play chess very differently than humans, so a move that's easy for an engine to find (and therefore discovered at a lower depth), might be difficult for a human to spot.
Different Game Stages
After looking at the performance on all kinds of puzzles, I thought that it might be interesting to look at them separated by the stage of the game. Luckily, the Lichess database includes a column with themes where the game stage is recorded. So I split the puzzles into openings, middlegames and endgames.
I wanted to look at these stages separately since I thought that the models might perform better in the earlier stages of the game. The reason for my suspicion was that the models were trained on human games and so will have seen more opening and middlegame positions than endgames. My tests confirmed my suspicion: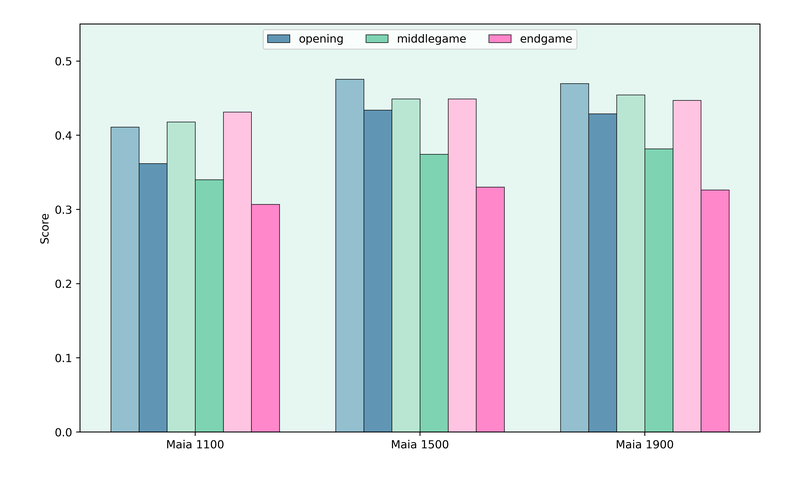
The score of Maia 1100 for partial solutions is actually highest in the endgame, but I think that this is due to “guessing” the first move correctly instead of being stronger at endgame puzzles. Otherwise, the full solutions should also have a higher score.
Conclusion
I was very fond of the idea of determining the level of mistakes using the Maia networks, so I'm a bit disappointed that it doesn't work as I had hoped. But I found it very interesting to look at the performance of these models on puzzles, since I had no idea before how strong they were.
If you have any ideas or suggestions for using the Maia networks, let me know.
I'm also still thinking about different ways to classify the level of a mistake, but currently I don't have any idea which seems suitable for human play.
If you enjoyed this post, check out my Substack.
More blog posts by jk_182

Comparing Stats from Erigaisi's Open and Closed Tournaments
Recently, I got very interested in the play of Arjun Erigaisi, not only because he made the jump int…
Opening novelty rates of the 2024 Candidates
Who played the most novelties in the Candidates?
The Candidates in 13 Graphs
Looking at stats from the 2024 Candidates tournament